量化策略中常见的七种错误
量化投资新手在执行回测和建立量化模型时应注意下面这七个“大坑”。其中,有些误区可能很常见,但其影响力却往往被人忽略,有些误区可能在学术界和实践者的研究中司空见惯,通常我们也把他们视为理所当然。
1、幸存者偏差(Survivorship bias)
幸存者偏差是投资者面对的最普遍问题之一,而且很多人都知道幸存者偏差的存在,但很少人重视它所产生的效果。我们在回测的时候倾向于只使用当前尚存在的公司,这就意味我们剔除了那些因为破产、重组而退市的公司的所产生的影响。
在对历史数据进行调整时,一些破产、退市、表现不佳的股票定期都会被剔除。而这些被剔除的股票没有出现在你策略的股票池里,也就是说对过去做了回测时只利用了现在成分股的信息,剔除了那些在未来因为业绩或者股价表现不好而被剔除出成分股中股票的影响。
下图中显示了MSCI欧洲指数成分股等权重作为一个投资组合在过去的表现。蓝线为正确的投资组合,红线为存在幸存者偏差的组合。可以发现红线的投资回报率明显高于蓝线,从而使在回测时高估投资组合的收益。而更令人震惊的是,在做因子分析时,它有可能带来完全相反的结果。

也就是说当我们使用过去30年中表现最好的那些公司进行回测时,即便一些公司当时的信用风险高,当你知道谁会幸存下来时,于是在信用风险高或者陷入困境时买入,收益非常高。若考虑进那些破产、退市、表现不佳的股票后,结论则会完全相反,投资高信用风险企业的收益率长期远低于信用稳健的企业。
2、前视偏差(Look-ahead bias)
作为“七宗罪”之一的幸存者偏差是我们站在过去的时点上无法预知哪些公司能幸存下来并依旧是今天的指数成分股,而幸存者偏差仅仅是前视偏差的一种特例。前视偏差是指在回测时,使用了回测当时还不可用或者还没有公开的数据,这也是回测中最常见的错误。
前视偏差的一个很明显的例子就体现在财务数据上,而对财务数据的修正则更容易造成难以发现的错误。一般来说,每个公司财务数据发布的时间点不同,往往存在滞后。而在回测时我们往往根据每个公司数据发布的时间点去评估公司财务状况。
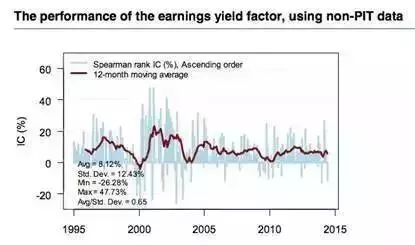
但是,当时点数据(Point-in-time data,简称PIT data)不可获得时,财务报告的滞后假设往往是错误的。下图即印证了采用PIT数据与非PIT数据所造成的差异。同时我们在下载历史宏观数据时往往得到的经过修正后的终值,但很多发达国家GDP数据发布后要经过两次调整,各大公司财报的修正也经常会进行修正。
在我们进行回测的时间点,终值往往尚无可知,只能使用初始值进行分析。可能有些人认为微小的修正并不会影响结论,但实际情况显示:很多宏观数据根据初值进行回归结果并不显著,公司财务数据的调整将对选股结果产生直接影响。

3、讲故事(The sin of storytelling)
一些人喜欢没有任何数据就开始讲故事,做量化的人喜欢拿着数据和结果讲故事。两种情况有很多类似之处,擅长讲故事的人或者说擅长解释数据结果的人往往在得到数据之前,内心已经存在既定的脚本,只需要找到数据支撑即可。
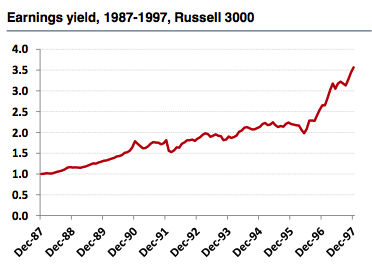
回顾1997年-2000年和2000年-2002年两段时间的美国科技成分股和Russell 3000指数,我们会发现一个截然相反的结论。从1997-2000年间的美国科技成分股来看,利润率是一个很好的因子,且回测结果也十分可信,然而如果拉长时间区间到2002年,我们会发现利润率指标不再是一个好的因子。


但从Russell 3000指数的市场表现来看,我们却得到了相反的结论,利润率指标仍然是一个有效的因子,可见,股票池的选取和回测的时间长短对因子的有效性判断影响非常大。所以讲故事的人并不能得到正确的结论。
市场中每天都在发现新的“好因子”,寻找永动机。能够发布出来的策略都是回测表现良好的。虽然讲故事的人对历史的解释非常动听,但其对未来的预测几乎没用。
金融经济中的相关性和因果性往往很难弄得清楚明白,所以,当我们做出和常识相悖或是和原来判断相符的结果时,最好不要去做一名讲故事的人。
4、数据挖掘(Data mining and data snooping)
数据挖掘可以说是目前备受关注的领域,基于海量的数据与计算机的算力支持,人们往往希望能够得到难以察觉的“好因子”。但是原有的金融数据还未及海量,且交易数据并不满足“低噪音”的数据前提。
有时数据挖掘几乎是无效的。例如,对标普500指数采用两种不同的因子加权算法建模,选择2009-2014年数据进行回测。
结果显示,采用2009-2014年数据筛选出6个表现最好的因子,使用等权重算法进行回测的结果非常完美,而采用历史数据进行样本外回测的结果却是一条直线。


因此,在构建策略或者寻找“好因子”时,我们都应该有清晰的逻辑和动机,量化分析只是验证自己的逻辑或动机的一种工具,而不是寻找逻辑的捷径。一般而言,我们构建策略或寻找因子的动机多源于金融学基础理论知识、市场的有效性、行为金融学等领域。当然,我们也并不否认数据挖掘在量化领域的应用价值。
5、信号衰减、换手率、交易成本
信号衰减指的是一个因子产生后对未来多长时间的股票回报有预测能力。一般来说,高换手率和信号衰减有关。不同的股票选择因子往往具有不同的信息衰减特征。越快的信号衰减往往需要更高的换手率去攫取收益。
然而,更高的换手率往往也意味着更高的交易成本。在组合构建中添加换手率约束是一个相对简单的方法,但并不是最理想的方法,因为换手率限制有时会帮助我们锁定收益,有时也会损害既定的组合表现。因此,权衡信号衰减、交易成本以及模型预测能力是构建投资组合的关键。
那么,如何确定最优的调整频率呢?我们需要注意的是,收紧换手率约束并不意味着降低调整频率。例如,我们常常听到类似“我们是长期价值投资者,我们预期持有股票3-5年。
因此,我们一年调整一次即可”。但是,信息往往来的很快,我们需要及时调整我们的模型和预期。即使我们的换手率约束很紧,我们仍然需要在适当时机加快调仓频率。下图以一个衰减速度很快的因子的极端案例为例进行说明。

当每天收盘时买入当天表现最差的100个股票,卖出过去的持仓,持续每日交易,回报率非常高。这里的错误也是前视偏差,还没收盘我们并不知道当天哪些股票表现最差,即使用程序化交易,这种策略也是不可行。我们只能以每天开盘价买入昨天表现最差的100个股票。通过对比,以开盘价买入的策略几乎一条直线。
6、异常值(Outliers)
传统的异常值控制技术主要包括winsorization和truncation两种,数据的标准化也可近似看做异常值控制的方法之一,标准化技术有可能对模型的表现产生显著的影响。比如下图中的标普BMI韩国指数成分股的利润率,采用平均值、剔除1%、2%极值等方法的结果差异很大。宏观数据中经常出现此类问题,少数极值若不做预处理,会严重影响回归结果。

虽然异常值有可能包含着有用的信息,但是大部分情况来看,他们并不包含有用信息。当然,对于价格动量因子来说是例外。
如下图所示,蓝线是去除了异常值后的组合表现,红线是原始数据。我们可以看到原始数据的动量策略要远远好于去除异常值后的策略表现。也就是说异常值包含了很大一部分信息,如果我们在做标准化时去除了异常值,我们就相当于损失了很大一部分信息。因此,最好的办法是对数据进行微观层面的聚合然后再计算总的指标。

7、非对称性
一般来说,做多因子策略时较常用的策略是多空策略,即做多好的股票同时做空差的股票。可惜的是,并不是所有的因子都是平等的,多数因子的多空收益特征存在不对称性,加之做空可能存在的成本和现实可行性,也给量化投资造成了不小的困扰。
下图展示了因子的多空收益特征,按照差异大小进行排列。越靠上的因子由于做空需求旺盛以及较高的交易成本,越难以攫取超额alpha。同时,我们可以看到,价值因子往往从做多端获得收益,而价格动量因子和质量因子更多的依靠做空端获得更多的alpha。分析师修正因子倾向于拥有更对称的多空收益特征。

上一篇:什么是股票指数?它有什么作用?
下一篇:上证50ETF期权做空好做吗?